
Коронавирус разбор слова по составу
Описание
Как разобрать слово по составу
Морфемный разбор слова или разбор по составу - это нахождение всех необходимых частей слова (корень, суффикс, окончание и т. д). Данный принцип является одним из основных в русскоязычной грамматике, поэтому морфемный разбор имеет немаловажное значение. Например, для того, чтобы определить, какая буква пишется в том или ином слове, нужно сначала узнать, в какой части слова она находится. И в зависимости от этого, использовать нужное написание. Грамотный разбор слова является основой правописания. Для осуществления разбора нужно иметь общее представление о морфемах, а также знать определённый порядок действий.
Приставка. Это морфема, при помощи которой образовываются новые слова. Приставка находится перед корнем. При помощи приставочного способа образования слов чаще всего получаются одинаковые части речи. Например: ставить - переставить. На примере видно, что от глагола при помощи приставки пере- образовался новый глагол. В русском языке также присутствуют заимствованные от других языков приставки. Например: анти-, де-, суб- и так далее.
Корень слова. Корень считается основной частью любого слова. В нем закладывается общее его значение, а также значение однокоренных слов (тех, у которых одинаковый корень). Однокоренных слова не обязательно должны относиться к одной части речи, они могут быть различными (от существительного образовываться в прилагательные и т. д.). Однако встречаются слова, которые имеют созвучные и похожие корни, но в то же время имеют отличные друг от друга значения. В таких случаях слова не считаются однокоренными, а называются омонимами. Для того, чтобы выявить корень слова, необходимо попытаться подобрать к нему однокоренные слова и найти ту общую часть, которая присутствует в каждом слове и остаётся неизменной. Обязательное условие: слова должны иметь похожее лексическое обозначение, а не просто созвучный корень. Например: дом - домик - домашний. Данные слова имеют одинаковую часть слова дом-, а значит она и является корнем.
Игра - игровой - играть. В этой цепочке слов общей частью является игр-, значит она также является корнем.
Суффикс. Это также одна из части слов, которая помогает образовывать новые слова. Морфема находит свое расположение после корня слова. Кроме того, суффикс помогает менять саму форму того или иного слова, а также образовывать новые части речи. Чаще всего существительное и прилагательные. Например: лес - лесник. Благодаря суффиксу -ник- образовалось новое существительное. Море - морской. При помощи суффикса -ск- от существительного образовалось новое прилагательное. Стоит заметить, что морфема не считается основной частью слова, суффикса попросту может не быть в составе. Чтобы найти данную морфему, нужно для начала определить корень и окончание слова. То, что останется между ними, и будет суффиксом. Важно знать, что оставшаяся часть слова не всегда является цельным суффиксом. Их может быть и несколько.
Окончание слова. Окончание является изменяем ой частью слова, которая зависит от рода слова, числа и падежа. Данная морфема обычно идёт после корня либо суффикса. Окончание несёт роль связывание слов в предложениях. Как же его определить? Нужно просто просклонять нужное слово и понять, какой части присуще меняться. Это и будет окончанием слова. Например: трава, травы, траве. Просклоняв слово в разных падежах, можно увидеть, что изменяется только последняя буква, а значит она и является окончанием.
Окончание также может иметь и нулевую форму. Для того, чтобы его определить, нужно также просклонять нужное слово по падежам. Если в падежных формах появляются новые буквы, значит начальная форма слова имеет нулевое окончание. Например: дом, дома, дому. В падежных формах слово приобрело окончание, значит изначально оно являлось нулевым.
Соединительные буквы. Это буквы, которые соединяют несколько корней в сложнообразованных словах. Наиболее распространены сединительные гласные -о- и -е-. Например: птицелов, кровожадный, самолёт.
Основа. Это часть слова, не входящая в состав окончания и остающаяся неизменной.
Определить, с какой частью речи придётся работать. Это можно сделать путем подбора вопроса к слову.
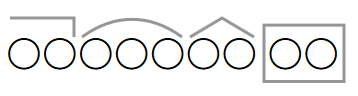
Теперь нужно определить окончание имеющегося слова. Для этого стоит просклонять его по числам и падежам. Та часть, которая изменилась, обводится в квадрат. Так обозначается окончание. Первоначальный поиск окончания является обязательным правилом для всех школьников. Ведь некоторые из них начинают морфемный разбор именно с выделения корня. Это является одним из самых ошибочных заблуждений, потому что в некоторых словах определить корень довольно сложно, а где-то его и вовсе нет.
Следующее действие - найти основу. Сделать это несложно. Часть слова, оставшаяся после выделения окончания, и является основой. Подчёркивается она одной горизонтальной линией, которая немного приподнимается перед окончанием.
Определить корень слова. Чтобы это осуществить, нужно подобрать однокоренные слова к нужному слову. Они должны быть похожи по лексическому значению, то есть быть похожими по смыслу, а не только по звучанию. Та неизменная часть, которая присутствует во всех словах и будет являться корнем. Обозначается он специальной дугой над нужной буквенной частью.
Выделить суффиксы. Для этого нужно сопоставить конкретное слово с его прочими формами. А затем создать словообразовательную цепочку, чтобы понять, какое слово было первоначальным, и какой суффикс использовался в процессе. Обозначается морфема формой полуромба над нужной частью слова.
Найти приставку. К конкретному слову нужно попытаться подобрать другие приставки. Также можно использовать другие слова с применением имеющейся приставки. Если смысл слова не коверкается, значит эта часть слова является приставкой. Выделяется она горизонтальной линией над словом, которая загинается перед корнем.
Совсем недавно мы столкнулись с необходимостью HTML-верстки большого количества разнообразного учебного (школьная программа) материала.
К сожалению, в ряде случаев пришлось отдельно готовить изображения с текстовыми блоками, которые были снабжены хитрой версткой. Это усложняет процессы HTML-верстки и внесения правок. Благодаря замечательному MathJax, мы смогли оптимизировать верстку в части математики, физики и неорганической химии, однако органическая химия осталась непобежденной. Да, есть пакеты для верстки структурных формул в LaTex, но в MathJax их поддержки нет.
Взять, к примеру, морфемный анализ слова (разбор слова по составу). Тут, увы, тоже готовых решений не нашлось… Встретились единичные случаи в Сети: некоторые сайты внедрили собственные решения, но несвободные и недокументированные. Кроме того, не очень удобные для верстки. В остальных же случаях (которых большинство) — опять-таки вставка заранее сделанных изображений. Почти всегда — растр.
Поэтому, готовясь к новым материалам, а также давно желая попробовать разработку на GitHub, я решил на досуге сделать простенький js-движок для отрисовки условных обозначений морфем. Работа сырая, но я буду рад, если кто-то присоединится, покритикует код (разумеется, там есть что критиковать) или вспомнит при необходимости о Морфане в будущем.
Позже планируется также библиотека для отображения условных обозначений синтаксического разбора предложения.
Присылаем лучшие статьи раз в месяц
Скоро на этот адрес придет письмо. Подтвердите подписку, если всё в силе.
- Скопировать ссылку
- ВКонтакте
- Telegram
Похожие публикации
- 10 марта 2018 в 02:28
Заказы
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Комментарии 41
Удручает далекий от международного DSL: ko, ok мало что скажут англоговорящему программисту, которому захочется воспользоваться такой замечательной наработкой.
') — временный div создается каждый раз при вызове функции — не бог весть какая нагрузка, но все же дешевле создать его заранее, а в этом месте только клонировать.
newNode = document.createElement('span'); jQuery(newNode).css('letter-spacing','normal'); — то же самое.
Удручает так же отсутствие поддержки AMD/UMD.
В остальном штука нужная и полезная, спасибо!
Благодарю за детали!
Повторяемость кода — согласен. Практически ничего не оптимизировал еще. А насчет того, что клонирование дешевле, чем создание — удивлен! Попробую.
Насчет DSL — спорно. С одной стороны код и комментарии привел (пока не до конца) в состояние, понятное англоязыному. Пока испытываю сложности с переводом специфических терминов и в целом пишу слабо, только читаю. Но эта работа сделана будет. А вот касательно названий морфем — тут я как раз специально остановился на сокращенных транслитах. Бибилиотека всё-таки нужна только для русского языка. Не поверите — до сих пор не смог найти никакого стандарта по условным обозначениям. Что уж говорить про зарубежье. А в серьезной науке уже не пользуются таким обозначениями — только в школе. Поэтому, я нацелен сделать библиотеку максимально простой для рядового пользователя, который чуть-чуть знает HTML. Если библиотека будет востребована, то по двум направлениям: сайты по русскому языку, электронные издания по русскому языку (аналоги EPUB.)
Насчет AMD/UMD стоит подумать, согласен. Но пока надо доработать функционал. Хотелось бы все-таки охватить MSIE8, добавить некоторые специфические условные обозначения и реализовать кое что в API для удобства создания интерактивов (редактирования разметки слова с помощью инструмента выделения)
Сделал PR с враппером, думать там нечего, механическая работа.
Насчет терминов все-таки не соглашусь. Когда работаешь с кодом, мозг автоматически переходит на английский язык, а тут вдруг какой-то nullok нна тебе когнитивным диссонансом по организму:)
В крайнем случае буду ковырять Cufon, MathJax и разбираться с VML.
Но ситуация такова: в моей основной работе мне приходится ориентироваться в основном на WebKit. Так что, потихоньку.
А вы думали о реализации на голом CSS?
Тут вот какое дело:
1) морфемы могут пересекаться. Кстати, чем дальше я влезаю в предметную область, тем больше удивляюсь :)
2) в моем варианте, imho, удобнее и понятнее сама разметка. А библиотека ориентирована на начинающего пользователя.
3) проще автоматизировать разметку, если прицепиться к сервису, который по словарю делает разбор.
4) проще код интерактива, который позволяет вживую разметить. Он готов, но есть непонятные баги, поэтому не выложен.
Сейчас библиотека лезет в DOM минимально: добаляет svg и span-ы вокруг букв окончаний, чтоб сделать отступы.
В ближайшее время придется добавить что-то еще, чтобы svg элементы положить под слово. Тогда текст в окончании будет кликабельным. Это к предыдущему каменту, кстати.
Так вот, если морфемы перескаются, как мне одну и ту же букву запихнуть в два разных span-а? Не вложенных, как в случае, когда корень и суффикс входя в основу. А именно пересекающихся.
Хотя, конечно, да, проблем с определением размером морфем и позиционирования svg не было бы :)
Спасибо, поправлю опечатку.
Может быть вы правы. Но я ориентировался на транслит.
Насчет двухбуквенности — хотелось лаконичности, но сейчас уже вылезают проблемы с тем, что двух букв будет недостаточно.
Дело в том, что условные обозначения для морфем различаются в разных источниках.
Не всегда могут договориться, что какой морфемой является, а уж обозначения — тем более. Никакого стандарта нет.
Более того, в ряде источников приводятся корни, которые отмечаются снизу слова. Это как раз для случая пересечений морфем.
Я некоторые время погуглил, поспрашивал знакомых редакторов-предметников, профильные форумы.
Толку мало. Набираешь разные школьные словари и учебники, интегрируешь и всё реализуешь.
Так что, может быть, как устаканится — можно будет добавить и такой синтаксис команд.
Спасибо, посмотрю внимательно. Но, после беглого ознакомления, не понял — к специфической верстке, для которой у нас используется MathJax и вот теперь Морфана, оно — как?
В принципе, у нас нет проблем с версткой материалов в целом. Развиваем классификацию материалов, делаем шаблоны. Потихоньку совершенствуем. Вот таких штук, про которые я написал в посте немного, но они есть. Органическая химия — самая проблема :)
P.S. Я — за решения WYSIWYM!
Оно потенциально к любой верстке. C MathJax есть пример с ленивой загрузкой в разделе компоненты. Морфемы легко. Любой подход или библиотеку можно легко обернуть в виде компонента и затем использовать с ленивой загрузкой в верстке и со статической в продакшене.
html это ассемблер веба, html страшно далек от этого принципа, и при росте количества страниц осмысленного текста и с необходимостью правок если у вас будет использоваться html, шаблоны, вы погрязнете. А разметки форматирования значительно ближе к этому принципу.
И с органической химией наверное можно было бы что-то придумать, надо бы конкретный пример.
в чем сакралный смысл подключать конфиги так:
И потом делать так:
Ну, подглядел у MathJax и упростил. Они, правда не затирают, а ставят отметку о факте обработки блока конфига. А сам код пихают в очередь обработки, а я сразу в eval.
А в чём криминал?
У меня была задача — минимум кода для дефолтного варианта использования библиотеки: подгрузилось — само запустилось — готово.
Для пользователя с минимумом требований.
А вот если нужно конфигурировать, то сперва нужно запретить автозапуск.
Был еще вариант — дописывать в script в путь к js-файлу параметры. Также делает MathJax. Но это, imho, хуже. И всё равно парсить и обрабатывать.
Я не вижу в чем сложность вот это:
заменить на это:
И вообще выкинуть кусок с eval. Зачем он нужен?
Все верно, код начинает работать сразу после загрузки, но у вас блок инициализации и чтения конфигов, расположен внутри:
А это значит что вы начинаете работать в момент когда загружены все скрипты, стили и картинки, вставленные на странице.
И по этому если подключить сначала библиотеку а потом ее конфиги, то часть кода с eval можно выкинуть.
И вот эта функция:
Ого, какой мощный у вас подход. SVG, нагруженный JS, все дела.
А зачем так сложно? Почему не сделать на чистом CSS, а в JS оставить только морфологический разбор? Вот, наклепал proof of concept на CSS: sassmeister.com/gist/7328321
Конечно, не так красиво получается, как у вас, но ведь я потратил на это всего полчасика. С обозначением суффикса возникли неожиданные сложности, которые я так и не решил, но при желании можно допилить и сделать красиво.
Оставлять разметку span-ами на человека я не хотел — это усложняет ему задачу и, кроме того, пересекающиеся морфемы так не сделать (хотя, каюсь, я тогда о них не знал).
Допустим, я выбрал предлагаемый вами вариант и не думаю о пересечении морфем. Следовательно, основная задача библиотеки — правильно расставить span-ы. И вот тут я, конечно, нарушаю KISS, но предполагаю, что слово — это идеальный вариант. А может быть такой: сл . И, поверьте, такое встречается часто. Отмечают орфограммы в словах и тут же делаю морфемный разбор.
Сделайте ссылку в статье на официальный сайт, чтобы демо можно было сразу щупать.
В Опере 12.16 у меня что-то не так: prntscr.com/228tvu.
Помочь вопросу выделения окончаний имхо поможет CSS-свойство pointer-events: none, примененное на SVG-элементы (все браузеры, кроме IE до 10 включительно).
Идея хорошая, удачи вам с проектом!)
Ага, видел при тестировании на browsershots такое. Заливка контуров непрозрачна. Буду править.
Про pointer-events не слышал. Посмотрю, спасибо. Если это аналог mouseEnabled/mouseChildren из Flash — замечательно.
Только полноправные пользователи могут оставлять комментарии. Войдите, пожалуйста.
Разбор слова по составу (морфемный анализ, от слова морфема – значимая часть слова) – один из видов лингвистического анализа, целью которого является определение состава, или структуры, слова. Он играет значительную роль в формировании орфографических навыков.
Например, при написании прилагательных, образованных от существительных при помощи суффикса -aт, типа дощатый – брусчатый, важно определить, к какой морфеме относится буква кв производящем существительном: если к корню (доск-а), то в соответствующем прилагательном пишется щ, если к суффиксу (брус-ок), то – ч (после согласного корня).
Необходимо помнить, что разбор слова по составу следует производить в соответствии с нормами современного русского языка. Так, в современном русском языке слово богатый не имеет суффикса, который выделялся некогда и имел то же значение, что и в прилагательном полосатый, а именно: наличие соответствующего признака, предмета. В настоящее время прилагательное полосатый имеет отношение к слову полоса, т. е. мотивировано им, и, следовательно, содержит суффикс -aт, прилагательное же богатый утратило отношения производности с существительным бог, поэтому его основа состоит лишь из корня. При разборе слова по составу следует придерживаться определенного порядка выделения его частей, или морфем.
Основным приемом при разборе слова является подбор его форм (для выделения окончания), одноструктурных слов (для определения суффиксов и приставок) и однокоренных слов (для нахождения корня). Целесообразно при выделении той или иной морфемы определять ее грамматическое значение. На первых порах при освоении данного вида лингвистического анализа полезно даже записывать характеристику каждой части слова.
Окончание– это изменяемая, значимая часть слова, которая образует форму слова и служит для связи слов в словосочетании и предложении. Значение окончания чисто грамматическое: оно указывает на число и падеж у существительных, числительных и личных местоимений; падеж, число и – только в единственном числе – род у прилагательных, причастий и некоторых местоимений; лицо и число у глаголов в настоящем и будущем времени; число и род у глаголов в прошедшем времени и условном наклонении.
В русском языке существует значительное число слов, которые не имеют окончания в силу того, что не изменяются. Это:
- наречия,
- деепричастия,
- сравнительная степень прилагательного,
- некоторые существительные (пальто, шоссе),
- некоторые прилагательные (беж, мини),
- некоторые притяжательные местоимения (его, ее, их).
Основные формы и классы слов, в которых выделяются нулевые окончания:
Суффикс – значимая часть слова, которая находится после корня и обычно служит для образования слов (исключением является суффикс -ся (-сь), который находится после окончания). Суффиксы, так же как и окончания, могут быть материально выраженными и нулевыми.
Понятие нулевого суффикса не используется в школьной программе, однако практически, при разборе слов, учащиеся сталкиваются с явлениями, которые трудно объяснить без данного понятия. Это важно и при интерпретации такого явления, как бессуфиксный способ образования слов.
Нулевой суффикс выделяется в следующих случаях:
- форма прош. вр. и условного наклонения глаголов: берег^ (ср. берег-л-а ), занес^бы (ср. занес-л-а бы);
- ж.р. им.п. ед.ч. существительных, образованных от соответствующих прилагательных: синь^ (ср. синий => синь, синий => син- ев-а);
- им.п. ед.ч. м.р. отглагольных существительных: бег^ (ср. бегать=> бег^, бегать => бег-отн-я).
Суффиксы разных частей речи имеют свои особенности. У существительных они многочисленны, довольно конкретны и разнообразны по значению, которое вносят в слово: например, -тель- суффикс лица (читатель), -к- суффикс предмета (терка), -ость- суффикс отвлеченного признака (жизненность), -ний- суффикс действия (горение), -ушк- суффикс субъективной оценки (категория субъективной оценки – категория, выражающая отношение говорящего к предмету речи) (головушка).
Для суффиксов имен существительных характерно явление омонимии, например, суффикс -к- может иметь значение субъективной оценки (речка) и действия (пилка дров).
Суффиксы прилагательных по своей семантике более отвлеченны, чем суффиксы существительных. Можно указать на свойство суффиксов определять тот или иной разряд прилагательных, например, -лив- суффикс качественных прилагательных (терпеливый, надоедливый), -ск- суффикс относительных прилагательных (пушкинский (стиль), морской), -ое-, -ин-, -й- суффиксы притяжательных прилагательных: (отцов, Петин, бычий).
Глагольные суффиксы, как правило, лишены многозначности, они не создают разнородных семантических классов внутри категории глагола. В слове глагольные суффиксы легко узнаются и выделяются благодаря своему грамматическому значению, например:
- суффиксы временных форм: -л- (прошедшее время) – шел, пила; -й- (настоящее время) – чита[йу]т, летай;
- суффиксы основы инфинитива, или неопределенной формы глагола: -а-, -е-, -и-: гнать, темнеть, служить;
- видовые суффиксы -и-, -а-, -ну-, -ива-, -ива-, -ва-: украсить, украшать, крикнуть, сливать, прочитывать;
- суффиксы причастий -ущ-, -ащ-, -в-, -вш-, -н-, -ен-, -т, -ом-, -ем-, -им-: тонущий, купивший, забытый;
- суффиксы деепричастий -а-, -учи-, -в-, -вши-: спеша, летя, прочитав, пригнувшись.
Приставка – значимая часть слова, находящаяся перед корнем и служащая для образования слов. Приставка вносит в слово дополнительное значение по сравнению с исходным (съехать, въехать, выехать, объехать – указание на направление движения). В слове может быть несколько приставок (пере-раз-ложение).
Корень– главная значимая часть слова, в которой заключено лексическое значение слова, общее значение всех родственных (однокоренных) слов. Слова с одним и тем же корнем называются однокоренными, и их родственность устанавливается на основании значения, выражаемого корнем (ср. омонимичный корень в двух группах слов: вода – подводник – водяной и водитель – подвода – водить). В корне можно наблюдать явление, носящее название чередования. Чередоваться могут и гласные (собирать – соберу, гореть-гарь), и согласные (бегать – бежать, расти – выращивать), и те и другие одновременно (ращу -росток, проложить – пролагать).
Как уже говорилось, корень является последней морфемой, которая выделяется в слове. Этому правилу надо следовать неукоснительно, особенно если принять во внимание то, что один и тот же корень может выступать в словах в различных видах, например: веду, водить, вести; шла, шел, пришедший. Слово может иметь в своем составе один (вода, лес) и более корней (водовоз, лесоруб).
Порядок разбора
- Определить, какой частью речи является анализируемое слово, в какой форме оно употреблено.
- Если слово изменяется, выделить формообразовательные морфемы
- Выделить основу.
- В основе выделить корень, словообразовательные морфемы (если есть).
Образец разбора
Городской – прилагательное в форме мужского рода именительного падежа единственного числа.
Словообразовательный суффикс –ск-.
 | Фото: Элина Сугарова/ТАСС |
 | Фото: REUTERS/Dado Ruvic |
 | Фото: mskagency.ru |
- Дома в режиме самоизоляции
- В церкви
- Не праздную
- Снизились
- Не изменились
- Повысились


 |
 | 19 марта 2020, 20:00 Фото: ALEX PLAVEVSKI/ЕРА/ТАСС Текст: Евгений Крутиков |
В связи с пандемией коронавируса планету захлестнула и волна конспирологии, с этим вирусом связанная. Выдвигаются самые фантастические версии по поводу происхождения вируса, китайских сверхсекретных лабораторий и ошибок при разработке биологического оружия. Какие из этих публикаций выглядят наиболее правдоподобными и почему?
Пандемия конспирологии затронула практически все страны и народы, только отличается оттенками идеологической направленности. В США и на Украине уверены, что главный враг человечества – это Россия. В Китае обвиняют США. Часть конспирологических версий связана с якобы странностями в структуре вируса, что может свидетельствовать о его искусственном происхождении, и с особенностями его распространения. Другая часть (более аргументированная) связана со странностями вокруг генезиса вируса в конкретно взятом Ухане. И странностей действительно много.
Правда здесь только в том, что такая статья про анализ РНК-структуры вируса (без псевдовоенных выводов) в одном из индийских научных журналов действительно была. Потом выяснилось, что индусы криво запустили программу анализа генома и так же криво проанализировали кривые результаты. Статью перепроверили и отозвали. Именно отозвали, а не закрыли доступ. То есть статья не удалена, а есть в общем доступе с объяснением, что она отозвана и почему, но конспирологи никогда не читают то, что написано в сноске мелким шрифтом.
Больше никто в настоящей научной среде плодов для конспирологии не нашел, но странностей от этого меньше не стало. А странности плодят версии и своеобразную логику.
Китайский институт?
Затем в детективе появился новый персонаж – тоже женщина и тоже сотрудник, но уже лаборатории безопасности, а не самого института, по имени Чэнь Цзюаньцзяо.
В китайской социальной сети Weibo анонимный источник с ником Weiketiezhi сообщил, что якобы научный сотрудник Чэнь Цзюаньцзяо с целью наживы продала на рынке подопытных животных и тем самым выпустила на свободу синтезированный штамм вируса. Типичный сюжет для сериала. Институт вирусологии снова выступил с опровержением, но уже другого толка. Никак не комментируя факт существования гражданки с таким именем и фамилией и ее работу в лаборатории, в официальном ответе сообщили, что все это – слухи и вбросы, а пользователь с ником Weiketiezhi выходил в Сеть с иностранного IP-адреса.
А это уже совсем катастрофа. То есть в уханьской лаборатории с 2015 года реально опытным путем на неких животных синтезировали какие-то вирусы и затем пытались выяснить, передаются ли они людям и что из этого получается. Похоже, что получилось.
И заявившая это госпожа Ши не абы кто, а исследователь с мировым именем. Она в Университете Монпелье во Франции училась. А он в 1289 году основан, в нем Нострадамус и Энвер Ходжа учились, не к ночи помянутые.
Тут же возникли дополнительные вопросы. На каких именно животных ставились опыты? Неужели на летучих мышах? И куда потом делись подопытные экземпляры? Удалось ли госпоже Ши после 2015 года получить для своих опытов приматов? Если да, то какова их судьба? Мы догадываемся, что их судьба печальна, но насколько конкретно? Ну и самый главный вопрос: чем синтезированный китайскими учеными вирус отличается от природного? И есть ли разница между синтезированным вирусом и нынешним коронавирусом?
Молчание – нам ответ.
И российский след
Это помимо того, что он выдал американцам всю советскую научную систему в области биотехнологий и вирусологии.
Этническое оружие?
В целом вопросов очень много. Вопросов именно реальных, а не фантастических (хотя фантастических заметно больше). Проблема здесь исключительно в китайской стороне, которая на практике только множит всяческие подозрения.
Большинство ученых на данный момент однозначно утверждают, что пандемию вызвал именно самостоятельно мутировавший вирус, живший в летучих мышах, а госпожа Хуан Яньлин эту гадость съела. Этим поступком она и войдет в историю. Но на практике мы до сих пор не понимаем, что они там в Ухане в 2015 году синтезировали, на ком ставили опыты, сам ли мутировал вирус, насколько он похож на пандемический образец и многое тому подобное. А чем дольше у нас нет ответов на эти вопросы – тем больше конспирологических версий будет плодиться.
Читайте также:
